1. Introduction: Motivation and Significance
The characterization of dependencies within complex multivariate systems helps to identify the mechanisms operating in the system and understanding their function. Recent work has developed methods to characterize multivariate interactions by separating
n-variate dependencies for different orders
n [
1,
2,
3,
4,
5]. In particular, the work of Williams and Beer [
6,
7] introduced a framework, called partial information decomposition (PID), which quantifies whether different input variables provide redundant, unique, or synergistic information about an output variable when combined with other input variables. Intuitively, inputs are redundant if each carries individually information about the same aspects of the output. Information is unique if it is not carried by any other single (or group of) variables, and synergistic information can only be retrieved combining several inputs.
This information-theoretic approach to study interactions has found many applications to complex systems such as gene networks (e.g., [
8,
9,
10]), interactive agents (e.g., [
11,
12,
13,
14]), or neural processing (e.g., [
15,
16,
17]). More generally, the nature of the information contained in the inputs determines the complexity of extracting it [
18,
19], how robust it is to disrupt the system [
20], or how input dimensionality can be reduced without information loss [
21,
22].
Despite this great potential, the applicability of the PID framework has been hindered by the lack of agreement on the definition of a suitable measure of redundancy. In particular, Harder et al. [
23] indicated that the original measure proposed by [
6] only quantifies common amounts of information, instead of shared information that is qualitatively the same. A constellation of measures has been proposed to implement the PID (e.g., [
23,
24,
25,
26,
27,
28,
29]), and core properties, such as requiring nonnegativity as a property of the measures, are still the subject of debate [
29,
30,
31,
32].
A widespread application of the PID framework has also been limited by the lack of multivariate implementations. Some of the proposed measures were only defined for the bivariate case [
23,
24,
33]. Other multivariate measures allow negative components in the PID [
26,
29], which, although it may be adequate for statistical characterization of dependencies, limits the interpretation of the information-theoretic quantities in terms of information communication [
34]. Even though at the level of local information, negativity is regarded as misinformation and can be interpreted, for example, operationally in terms of changes in belief [
35], when considering information in the context of communication [
36], then interpreting it as the number of messages to be retrieved without error through a noisy channel requires nonnegativity; for example, assessing the information representation about multidimensional sensory stimulus across neurons, in particular the analyses of the information content of neural responses [
17,
37]. Among the PID measures proposed, the maximum entropy measures of Bertschinger et al. [
24] have a preeminent role in the bivariate case because they provide bounds for any other measure consistent with a set of properties shared by many of the proposed measures. Motivated by this special role of the maximum entropy measures, Chicharro [
38] extended the maximum entropy approach to measures of the multivariate redundant information, which provide analogous bounds for the multivariate case. However, the work in [
38] did not address their numerical implementation.
In this work, we present
MaxEnt3D_Pid, a Python module that computes a trivariate information decomposition following the maximum entropy PID of [
38] and exploits the connection with the bivariate decompositions associated with the trivariate ones [
28]. This is, to our knowledge, the first available implementation of the maximum-entropy PID framework beyond the bivariate case [
39,
40,
41,
42], see
Appendix B. This implementation is relevant for the theoretical development and practical use of the PID framework.
From a theoretical point of view, this implementation will provide the possibility to test the properties of the PID beyond the bivariate case. This is critical with regard to the nonnegativity property because, while nonnegativity is guaranteed in the bivariate case, for the multivariate case, it has been proven that negative terms can appear in the presence of deterministic dependencies [
30,
32,
43]. However, the violation of nonnegativity has only been proven with isolated counterexamples, and it is not understood which properties of a system’s dependencies lead to negative PID measures.
From a practical point of view, the trivariate PID allows studying new types of distributed information that only appear beyond the bivariate case, such as information that is redundant for two inputs and unique with respect to a third [
6]. This extension is significant both to study multivariate systems directly, as well as to be exploited for data analysis [
21,
44]. As mentioned above, the characterization of synergy and redundancy in multivariate systems is relevant for a broad range of fields that encompass social and biological systems. So far, the PID has particularly found applications in neuroscience (e.g., [
17,
37,
45,
46,
47,
48]). For data analysis, the quantification of multivariate redundancy can be applied to dimensionality reduction [
22] or to better understand how representations emerge in neural networks during learning [
49,
50]. Altogether, this software promises to contribute significantly to the refinement of the information-theoretic tools it implements and also to foster its widespread application to analyze data from multivariate systems.
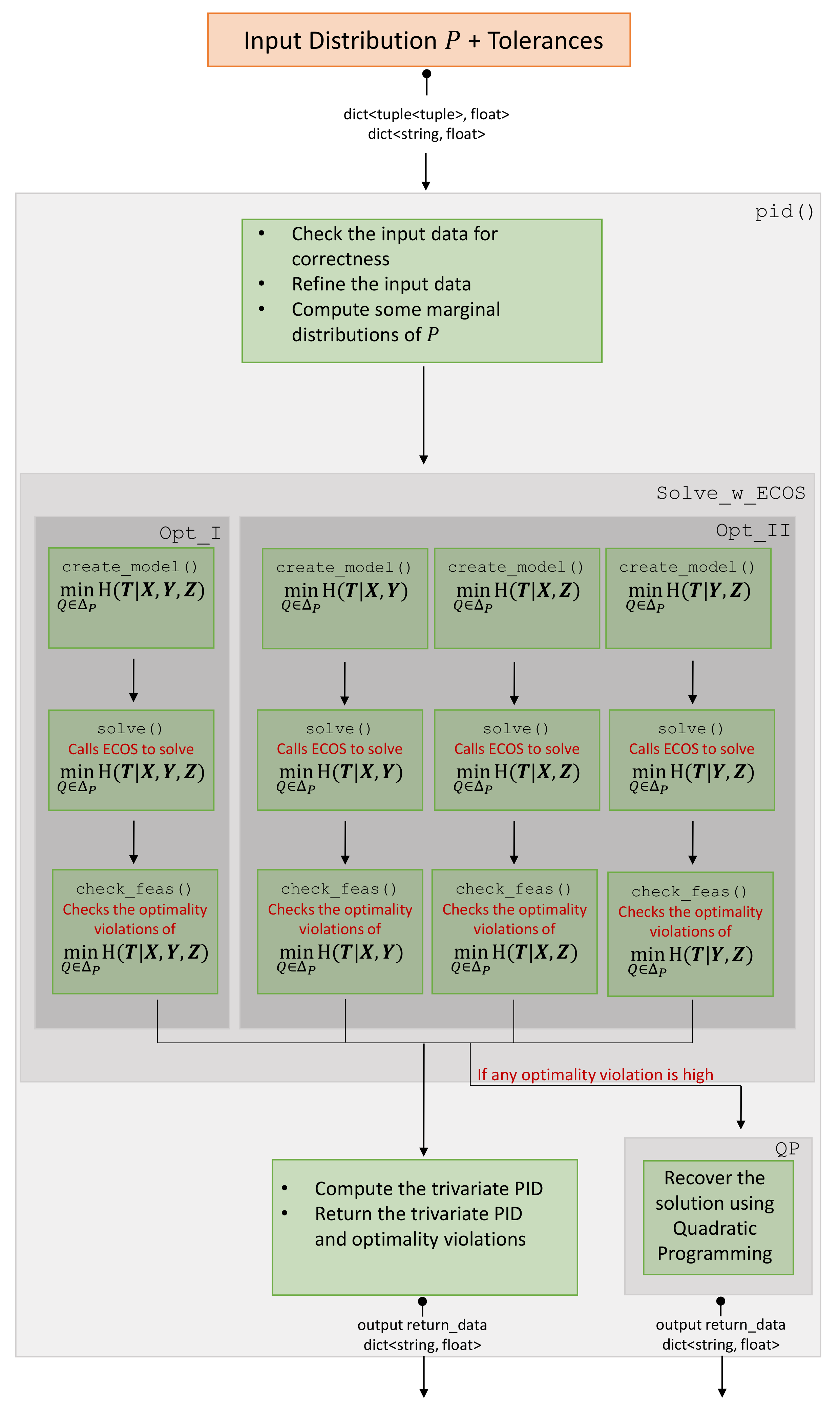
3. Illustrations
This section shows some performance tests of MaxEnt3D_Pid on three types of instances. We will describe each type of instance and show the results of testing MaxEnt3D_Pid for each one of them. The first two types, paradigmatic and Copy gates, are used as validation and memory tests. The last type, random probability distributions, is used to evaluate the accuracy and efficiency of MaxEnt3D_Pid in computing the trivariate partial information decomposition. More precisely, accuracy is evaluated as how close the values of and are to zero when has a considerably higher dimension, which is expected theoretically. The efficiency will be depicted in how fast MaxEnt3D_Pid is able to produce the results. The machine used comes with an Intel(R) Core(TM) i7-4790K CPU (four cores) and 16 GB of RAM. Only the computations of the last type were done using parallelization.
3.1. Paradigmatic Gates
As a first test, we used some trivariate PIDs that are known and have been studied previously [
25]. These examples are the logic gates collected in
Table 5. For these examples, the decomposition can be derived analytically, and thus, they serve to check the numerical estimations.
Testing
The test was implemented in
test_gates.py.
MaxEnt3D_Pid returns, for all gates, the same values as ([
25],
Table 1) up to a precision error of order
. The slowest solving time (not in parallel) was one millisecond.
3.2. Copy Gate
As a second test, we used the Copy gate example to examine the simulation of large systems. We simulated how the solver handled large systems in terms of speed and reliability. Reliability, in this context, is meant as the consistency of the measure on large systems and the degree to which the results can be trusted to be accurate enough.
The Copy gate is the mapping of , chosen uniformly at random, to , where The size of the joint distribution of scales as , where In our test, and , where .
Since and are independent, it is easy to see that the only nonzero quantities are for .
Testing
The test was implemented in
test_copy_gate.py. The slowest solving time was less than 100 s, and the worst deviation from the actual values was
. For more details, see
Table 6.
3.3. Random Probability Distributions
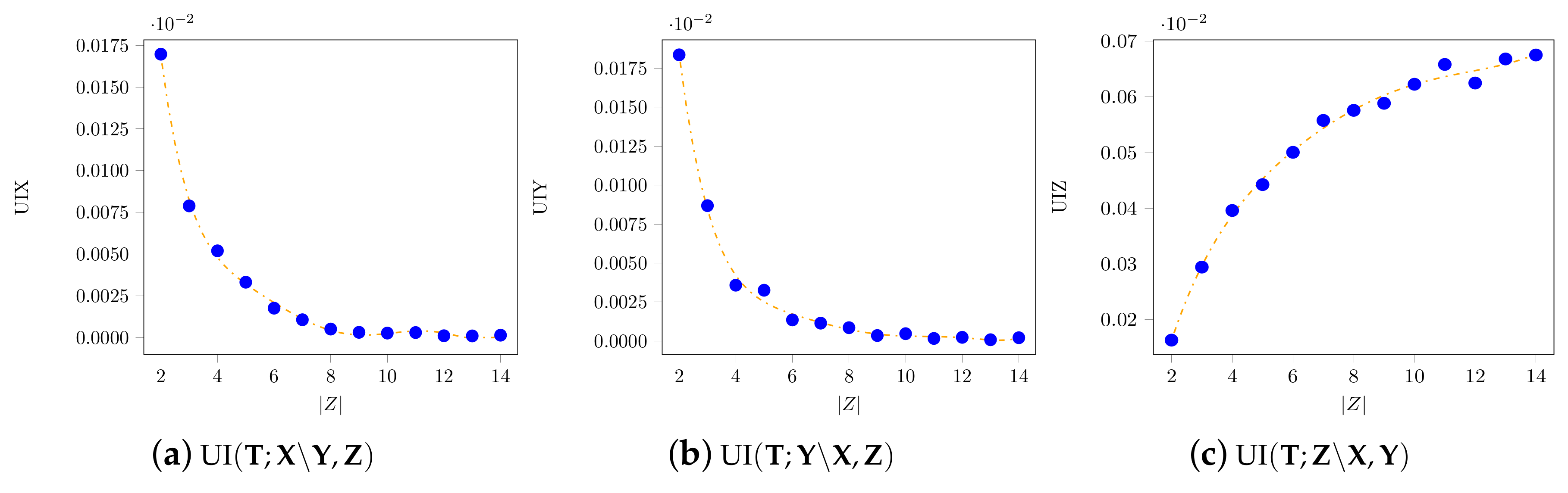
As a last example, we used joint distributions of sampled uniformly at random over the probability space, to test the accuracy of the solver. The size of T, X, and Y was fixed to two, whereas varied in . For each 500 joint distributions of were sampled.
Testing
As
increased, the average value of
and of
decreased, while that of
increased. In
Figure 6, the accuracy of the optimization is reflected in the low divergence from zero obtained for the unique information
and
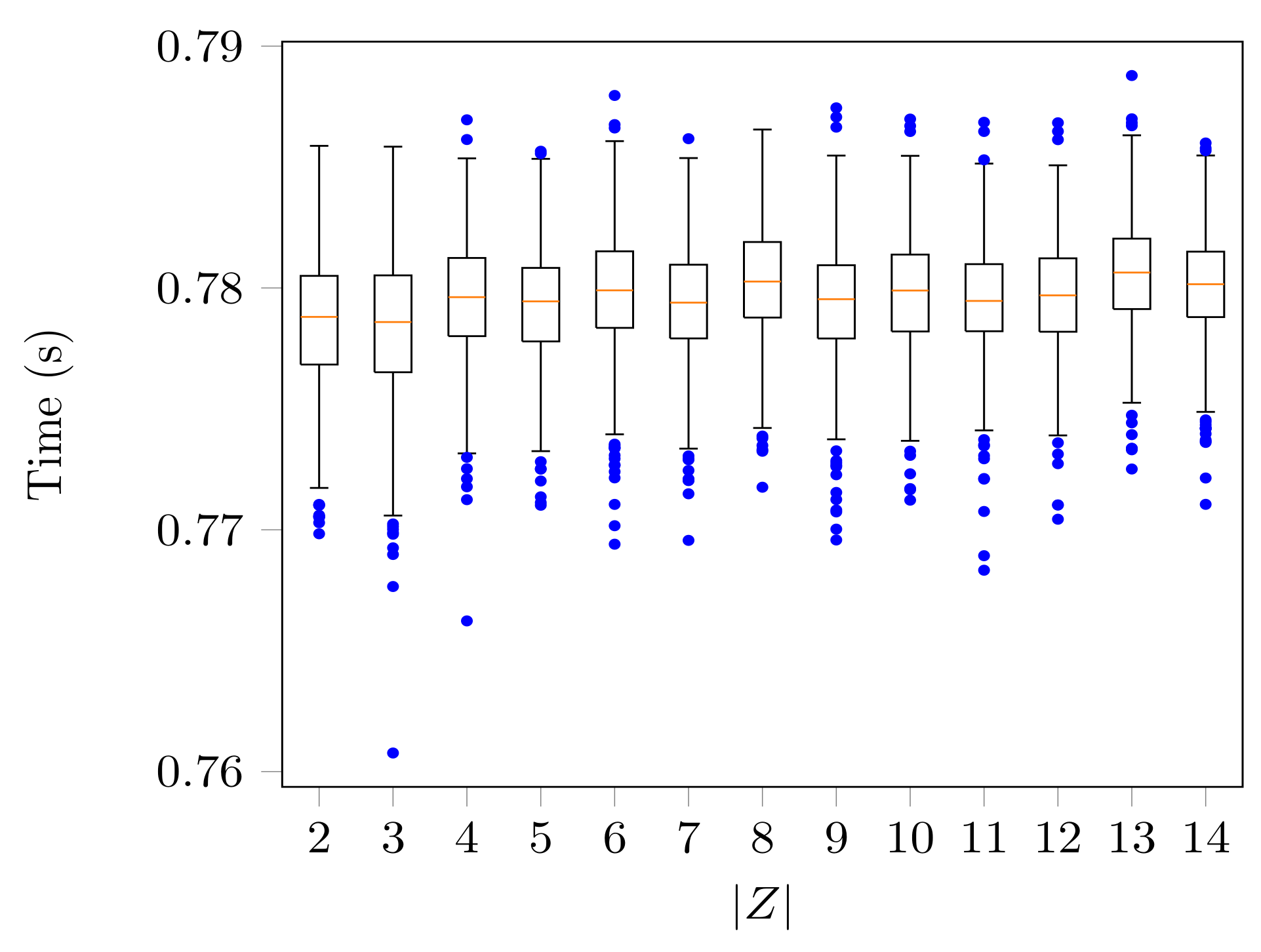
. In
Figure 7, the time has a constant trend, and the highest time value recorded was
s.
3.4. Challenging Distributions
We tested MaxEnt3D_Pid on randomly uniformly-sampled distributions, but with large sizes of T, X, Y, and Z. For each 500 joint distributions of were sampled where and The idea was to check with random and huge distributions (not structured as in the case of the Copy gate) how stable the estimator was.
3.4.1. Testing
For
some of the optimization problems (1a,b) did not converge due to numerical instabilities. This issue started to be frequent and significant when
for example 5% of the distributions had numerical problems in some of their optimization problems. We noticed that the returned solution from the non-convergent problem was feasible and far from optimal by a factor of 100 at most. The feasibility of the returned solution suggested fitting it along with the returned (optimal) solutions from the other convergent problems into the system of PID identities (
A12), which will reduce the optimality gap.
3.4.2. Recommendation
These challenging distributions have mainly two features, namely the high dimensionality of the quadruple and a significant number of relatively small (almost null) probability masses along with few concentrated probability masses. We suspect that these two features combined were the main reason for the convergence problems. Our approach was to use a quadratic programming (Class QP), which focuses on reducing the optimality gap and thus returns a close PID to the optimal PID (in case of no convergence problems).
Furthermore, we advise users to mitigate such distributions by dropping some of the points with almost null probability masses. Since the objective functions in (1a,b) are continuous and smooth (full support distributions) on
, then the PID of the mitigated distribution is considered a good approximation of that of the original distribution. Although we did not test this ad hoc on
MaxEnt3D_PID, the same technique was applied to such instances for
Broja_2PID ([
51], Chapter 5).
We speculated that when the solver will suffer dire numerical instabilities. It is recommended for the user to avoid large discrete binning resulting in humongous distributions.
3.4.3. Time Complexity
Theoretically, Makkeh et al. [
39,
51] showed that the worst running time complexity for solving (
1a) (the hardest problem computationally) was
where
Note that this time complexity bound was for the so-called barrier method, whereas
Ecos uses the primal-dual Mehrotra predictor-corrector method [
54], which does not have a theoretical complexity bound [
55].
4. Summary and Discussion
In this work, we presented
MaxEnt3D_Pid, a Python module that computes a trivariate decomposition based on the partial information decomposition (PID) framework of Williams and Beer [
6], in particular following the maximum entropy PID of [
38] and exploiting the connection with the bivariate decompositions associated with the trivariate one [
28]. This is, to our knowledge, the first available implementation extending the maximum-entropy PID framework beyond the bivariate case [
39,
40,
41,
42].
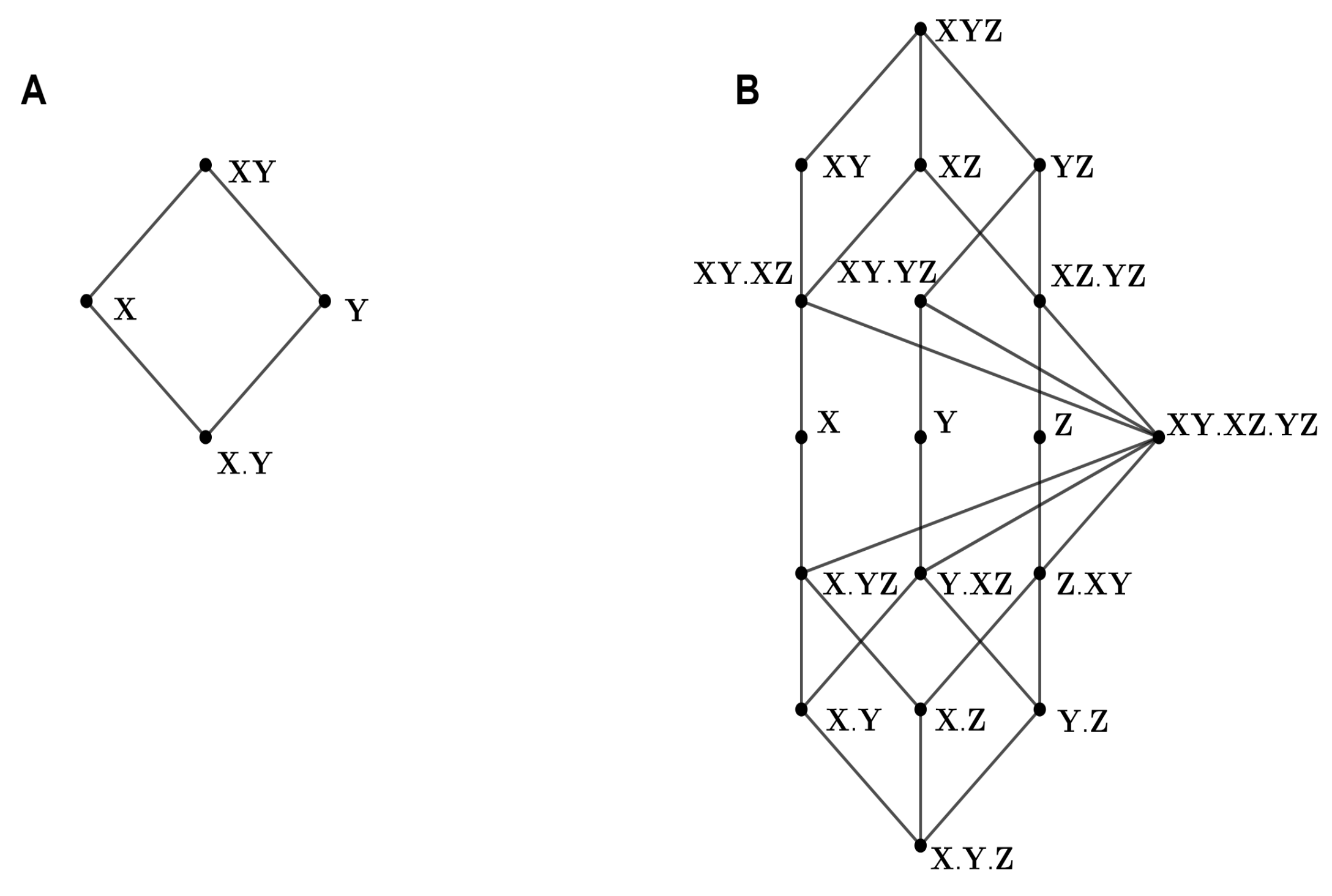
The PID framework allows decomposing the information that a group of input variables has about a target variable into redundant, unique, and synergistic components. For the bivariate case, this results in decomposition with four components, quantifying the redundancy, synergy, and unique information of each of the two inputs. In the multivariate case, finer parts appear, which do not correspond to purely redundant or unique components. For example, the redundancy components of the multivariate decomposition can be interpreted based on local unfoldings when a new input is added, with each redundancy component unfolding into a component also redundant with the new variable and a component of unique redundancy with respect to it [
38]. The PID analysis can qualitatively characterize the distribution of information beyond the standard mutual information measures [
56] and has already been proven useful to study information in multivariate systems (e.g., [
14,
17,
37,
56,
57,
58,
59,
60,
61,
62]).
However, the definition of suited measures to quantify synergy and redundancy is still a subject of debate. From all the proposed PID measures, the maximum entropy measures by Bertschinger et al. [
24] have a preeminent role in the bivariate case because they provide bounds to any other alternative measures that share fundamental properties related to the notions of redundancy and unique information. Chicharro [
38] generalized the maximum entropy approach, proposing multivariate definitions of redundant information and showing that these measures implement the local unfolding of redundancy via hierarchically-related maximum entropy constraints. The package
MaxEnt3D_Pid efficiently implemented the constrained information minimization operations involved in the calculation of the trivariate maximum-entropy PID decomposition. In
Section 2, we described the architecture of the software, presented in detail the main function of the software that computes the PID along with its optional inputs, and described how to use it. In
Section 3, we provided examples that verified that the software produced correct results on paradigmatic gates, simulated how the software scaled with large systems, and hinted to the accuracy of the software in estimating PID. In this section, we also presented challenging examples where the
MaxEnt3D_PID core optimizer had convergence problems and discussed our technique to retrieve an approximate PID and some suggestions to avoid such anomalies.
The possibility to calculate a trivariate decomposition of the mutual information represents a qualitative extension of the PID framework that goes beyond an incremental extension of the bivariate case, both regarding its theoretical development and its applicability. From a theoretical point of view, regarding the maximum-entropy approach, the multivariate case requires the introduction of new types of constraints in the information minimization that do not appear in the bivariate case (
Section 2 and [
38]). More generally, the trivariate decomposition allows further studying one of the key unsolved issues in the PID formulation, namely the requirement of the nonnegativity of the PID measures in the multivariate case.
In particular, Harder et al. [
23] indicated that the original measure proposed by [
6] only quantified common amounts of information and required new properties for the PID measures, to quantify qualitatively and not quantitatively how information is distributed. However, for the multivariate case, these properties have been proven to be incompatible with guaranteeing nonnegativity, by using some counterexamples [
30,
32,
43]. This led some subsequent proposals to define PID measures that either focus on the bivariate case [
23,
24] or do not require nonnegativity [
26,
29]. A multivariate formulation was desirable because the notions of synergy and redundancy are not restrained to the bivariate case, while nonnegativity is required for an interpretation of the measures in terms of information communication [
34] and not only as a statistical description of the probability distributions.
MaxEnt3D_Pid will allow systematically exploring when negative terms appear, beyond the currently-studied isolated counterexamples. Furthermore, it has been shown that in those counterexamples, the negative terms result from the criterion used to assign the information identity to different pieces of information when deterministic relations exist [
32]. Therefore, a systematic analysis of the appearance of negative terms will provide a better understanding of how information identity is assigned when quantifying redundancy, which is fundamental to assess how the PID measures conform to the corresponding underlying concepts.
From a practical point of view, the trivariate decomposition allows studying qualitatively new types of distributed information, identifying finer parts of the information that the inputs have about the target, such as information that is redundant for two inputs and unique with respect to a third [
6]. This is particularly useful when examining multivariate representations, such as the interactions between several genes [
8,
63] or characterizing the nature of coding in neural populations [
64,
65]. Furthermore, exploiting the connection between the bivariates and the trivariate decomposition due to the invariance of redundancy to context [
28],
MaxEnt3D_Pid also allows estimating the finer parts of the synergy component (
Appendix D). This also offers a substantial extension in the applicability of the PID framework, in particular for the study of dynamical systems [
66,
67]. In particular, a question that requires a trivariate decomposition is how information transfer is distributed among multivariate dynamic processes. Information transfer is commonly quantified with the measure called transfer entropy [
68,
69,
70,
71,
72], which calculates the conditional mutual information between the current state of a certain process
Y and the past of another process
X, given the past of
Y and of any other processes
Z that may also influence those two. In this case, by construction, the PID analysis should operate with three inputs corresponding to the pasts of
X,
Y, and
Z. Transfer entropy is widely applied to study information flows between brain areas to characterize dynamic functional connectivity [
73,
74,
75], and characterizing the synergy, redundancy, and unique information of these flows can provide further information about the degree of integration or segregation across brain areas [
76].
More generally, the availability of software implementing the maximum entropy PID framework beyond the bivariate case promises to be useful in a wide range of fields in which interactions in multivariate systems are relevant, spanning the domain of social [
12,
77] and biological sciences [
3,
10,
17,
63]. Furthermore, the PID measures can also be used as a tool for data analysis and to characterize computational models. This comprises dimensionality reduction via synergy or redundancy minimization [
19,
22], the study of generative networks that emerge from information maximization constraints [
78,
79], or explaining the representations in deep networks [
50].
The
MaxEnt3D_Pid package presents several differences and advantages with respect to other software packages currently available to implement the PID framework. Regarding the maximum entropy approach, other packages only compute bivariate decompositions [
39,
40,
41,
42]. The dit package [
42] also implements several other PID measures, including bivariate implementations for the measure of [
23,
27]. Among the multivariate decompositions, the ones using the measures
[
6] or
[
80] can readily be calculated with standard estimators of the mutual information. However, the former, as discussed above, only quantifies common amounts of information, while the latter is only valid for a certain type of data, namely multivariate Gaussian distributed. Software to estimate multivariate pointwise PIDs is also available [
26,
29,
81]. However, as mentioned above, these measures by construction allow negative components, which may not be desirable for the interpretation of the decomposition, for example in the context of communication theory, and limits their applicability for data analysis in such regimes [
22]. Altogether,
MaxEnt3D_Pid is the first software that implements the mutual information PID framework via hierarchically-related maximum entropy constraints, extending the bivariate case by efficiently computing the trivariate PID measures.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







